Retiring instance types?
Lifespan of cloud resources
TL;DR: AWS is building an interstellar spaceship.
Amazon Web Services is the canonical infrastructure cloud provider. EC2 beta was announced in 2006 and started with just one instance type: m1.small.
This day there are … a lot more instance types. From the simplified EC2 instance type & pricing page I can now count 27 different instance types: c1.medium, c1.xlarge, c3.2xlarge, c3.4xlarge, c3.8xlarge, c3.large, c3.xlarge, cc2.8xlarge, cg1.4xlarge, cr1.8xlarge, g2.2xlarge, hi1.4xlarge, hs1.8xlarge, i2.2xlarge, i2.4xlarge, i2.8xlarge, i2.xlarge, m1.large, m1.medium, m1.small, m1.xlarge, m2.2xlarge, m2.4xlarge, m2.xlarge, m3.2xlarge, m3.xlarge and t1.micro. Just try to say those aloud in one go!
This profileration is due to (I believe) three drivers: customer demand, enterprise adoption and advances in hardware. This is great, I have no gripes about the usefulness of the new instance types. I’ve had customer cases where “hi1.4xlarge” would have been the perfect solution but just was not yet available. Similarly the introduction of PIOPS and SSDs was a godsend for database-type workloads.

Death of Instances by … errr, actually it’s Takiyasha the Witch and the Skeleton Spectre by Utagawa Kuniyoshi (Image source: Wikimedia commons)
{kind=link}
Hardware generations
But what happens to old stuff? What about the old hardware? What about m1.small which has been around for 7+ years?
Currently the AWS instance types can be grouped to roughly three categories:
-
Shared core instance types (t1.micro and m1.small). Here vCPUs are not dedicated to an instance, but shared between multiple instances (50% for m1.small, no information on t1.micro but I’d expect its CPU allocation to be be both smaller and dynamic).
-
Generic instances which have 1 vCPU = 1 dedicated core, but otherwise don’t have any particular hardware affiliation — they are primarily defined by (vCPUs, memory, disk capacity) tuple. This includes all m1 and c1 class instance types (AWS specifies m1, m2 and c1 class instances to have “Intel Xeon Family” processor and t1’s as “Variable”.)
-
Hardware specified instances, e.g. instance types which are defined by particular hardware. This includes g2.2xlarge (“G2 instances provide access to NVIDIA GRID GPUs (“Kepler” GK104)”, from AWS) and c3 class (“Each virtual CPU (vCPU) on C3 instances is a hardware hyper-thread from a 2.8 GHz Intel Xeon E5-2680v2 (Ivy Bridge) processor”) among others. These also have 1 vCPU = 1 dedicated core.
GPU generation gaps
It is easy to see that the last category will pose difficulties in the future. The GK104 GPU is already a previous generation GPU with its successor (GK110) having been in production since May 2013 (both are based on the same GPU family architecture, e.g. Kepler). What happens when GK104 becomes unavailable?
-
AWS is not going to throw the g2.2xlarge machines to junk heap — after all, they’re going to be deprecated over 5 years. So when GK104 GPUs become unavailable, AWS is likely to keep g2.2xlarge around but crucially it is no longer able to increase g2.2xlarge capacity even if demand increases using GK104 alone.
(With one caveat, see end of this section.)
-
GK110-based machines can then be introduced as g2.4xlarge or other. Eventually, the successor to GK110 comes around and AWS faces the same situation as above.
(It makes no sense for AWS to roll GK110 GPUs into g2.2xlarge as even the lowest-specced GK110 die has 800 CUDA cores more. Why would they give those away at the same price?)
This leads to interesting economical dynamics. Let’s assume that year-to-year AWS purchases enough g2 class hardware to increase each instance type’s capacity by 100% and each hardware generation is on sale for 2 years, and that each new hardware generation will be initially purchased at same capacity as the previous generation. Looking at the graph below you’ll see that at year 3 the first-generation g2.2xlarge will represent one fifth of the total available capacity. (Caveat emptor: These values are completely arbitrary, so don’t rely on them even if they would seem sensible.)
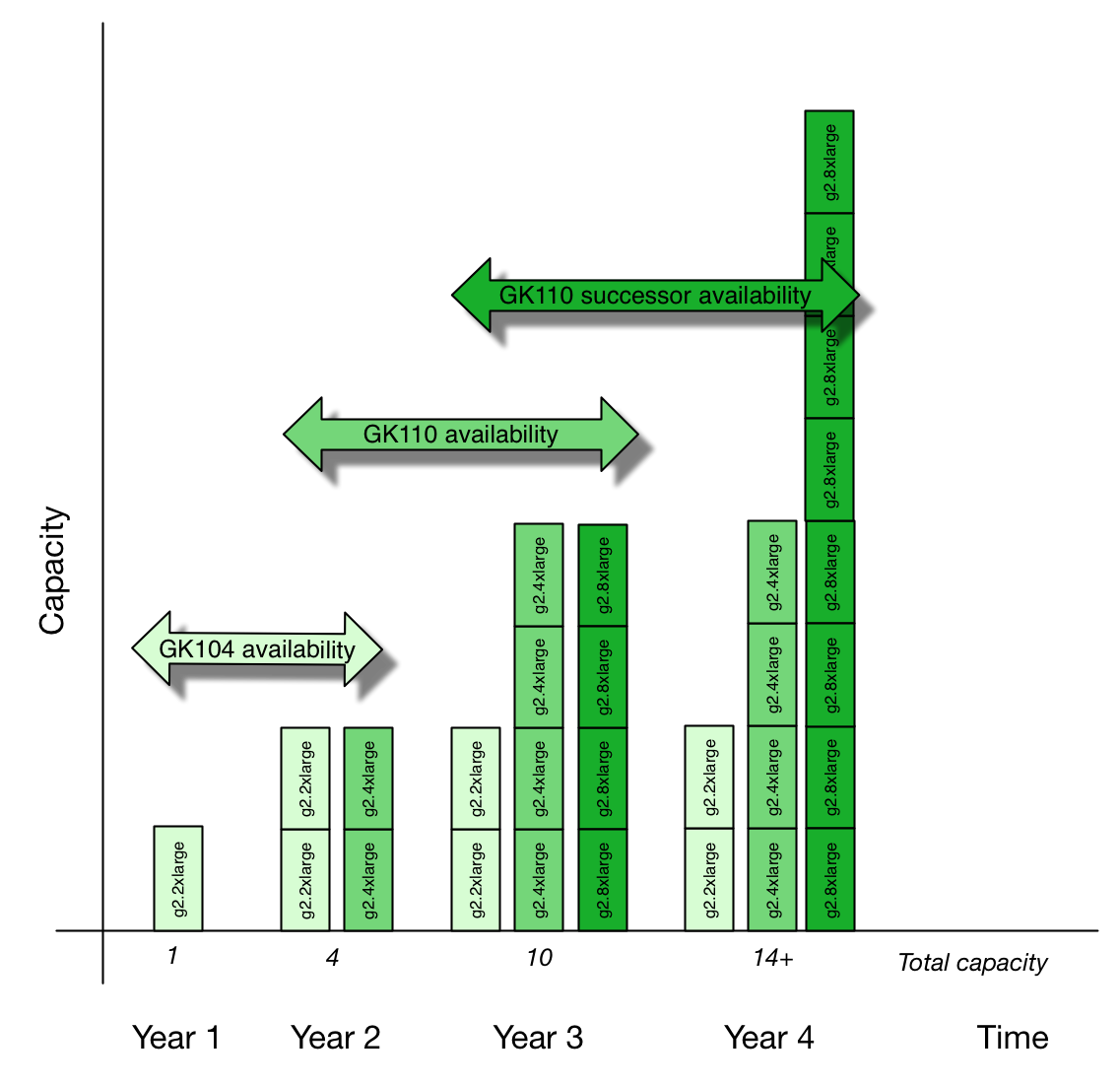
Note that I’m counting instances, not CUDA cores in the above graph! Also, the choice of 4xlarge and 8xlarge is arbitrary, they could be 3xlarge and 4xlarge equally well. My point is in hardware generations, not per-instance computing horsepower.
Assuming that in year 3 you are need some GPU horsepower, but you would be satisfied with g2.2xlarge. There are two potential outcomes:
-
There is spare capacity and you’ll get the g2.2xlarge on-demand instance.
Why would there be excess capacity available, assuming that the demand has grown from year to year? A possible scenario is that most of the demand has been satisfied with newer g2.4xlarge and g2.8xlarge instance types leaving the g2.2xlarge capacity underused.
That, of course, is a problem for AWS since they have hardware but no-one is paying for its use. (Opportunistic use of GPUs via spot market can provide some help, but in this case spot prices are going to be substantially less than on-demand prices thus not offsetting the loss of demand completely.)
-
Demand for GPU instances is much more evenly distributed, most likely due to people trying to pick up most cost-effective instance types. This means that demand for g2.2xlarge is substantial, yet since its total capacity (in this model) is just 1/5 of the total g2 class capacity your request is often blocked since no capacity is available.
This is problematic for you, of course, but it might be a publicity problem for AWS, too (“AWS unable to meet up to customer demand!” would the
tabloidsblogosphere scream.)
AWS is going to handle this situation somehow. It is possible to control demand via pricing. Future GPUs may support GPU virtualization (Kepler already has some hardware virtualization support) in a way that allows more flexible partitioning of GPU resources between multiple instances. They might do something else. I don’t know.
Anyway. If the first case happens and g2.2xlarge instances go fallow and there’s no demand for them after 1-2 years then how long is AWS going to keep them taking space in racks and costing maintenance effort? In this case there is bound to be a write-off at some point and the whole instance type would be nixed from inventory.
However even if they manage to keep g2.2xlarge instance demand up at some point hardware maintenance is going to exceed the marginal profit gained from keeping g2.2xlarge instances running instead of using the same space, electricity and personnel for something other. Since it is not possible to replace failed machines with identically speced machines (remember, GK104 no longer in production at that point), hardware failures are also going to slowly drain the instance type capacity down too.
So my final point is this: for instance types specified in terms of hardware, it is likely that they have a limited lifetime as that particular instance type (the hardware may live on, repurposed to serve another instance class).
When the underlying hardware becomes unavailable and that instance type’s capacity cannot be increased anymore, its fate is set. The maximum lifetime is the useful lifetime of the hardware (about 5 years), but due to economic reasons it may be also less.
CPU generations
Note that the above reasoning applies also to c3 and other classes that are specified by their CPU type. Yet, for CPUs the situation might be a little different. The t1, m1, m2 and c1 classes already run on multiple CPU generations. As Ou et al. show in their paper Exploiting hardware heterogeneity within the same instance type of amazon EC2 there are several CPU generations with different performance already deployed in AWS.
So for those instance classes which are not bound to a specific set of CPU or disk configuration AWS can just keep adding capacity using the current hardware generation. Yes, some customers get more recent (e.g. more powerful) hardware, but if you are really interested in raw performance these aren’t really your choice anyway.
Eventually c3 class with Intel Xeon E5-2680 will suffer the same fate as g2.2xlarge with Kepler GK104 — that specific CPU won’t be available indefinitely. Will AWS at this point introduce c4, and let c3 keep running as long as it is economically sensible?
Alternatively AWS may choose to re-define c3 to have a physical processor as “Intel Xeon E5-2680 or <whatever is the next generation>” and keep it running with the same caveats about hardware heterogeneity as t1/m1/m2/c1 classes.
One more possibility is that if AWS introduced c4, what would they do with c3 capacity in case its demand goes down? Since the hardware is completely capable of being serving the non-hardware specific instance types (t1/m1/m2/c1) it is possible that AWS decides to move any machines no longer in demand into “graveyard” instance types where the specific CPU classification is not relevant.
What lies in the future?
I have no idea how AWS plans to handle changes in hardware in the long run. Maybe they’ll keep adding new instance classes and types. Maybe they’ll re-define instance class specifications. Maybe something else happens.
While writing this post I came up with the following insights:
-
m1/m2/c1 generation-to-generation performance gap keeps growing. Eventually that gap between the first and latest generation may become too large so that it will affect their users detrimentally (“What? 2x difference between execution times on same instance type?”) if left unchecked.
The 1 vCPU = 1/2 core (m1.small) and 1 vCPU = 1 core guarantee (others) prevents more fine-grained core sharing in these (unless re-defined). It might be possible that AWS will move older generation machines into serving t1 class instances. They might even introduce t1.small, t1.medium or other t1 classes to supplement the t1.micro instance type (these wouldn’t get any vCPU-to-core matching guarantee, meaning less predictable performance profile) as well as to act as “graveyard” for servers from retired classes or from classes with substantially decreased demand.
-
c1 class feels the odd ball out. c3.large is better than c1.medium (being only $0.005 more expensive) and c3.2xlarge beats c1.xlarge ($0.040 increase). I don’t really see any reason to use c1 instances over c3 instances.
(Apart from the anecdotal information about low c3 instance availability, which I believe will eventually be sorted out.)
BTW, the same applies between m2.xlarge ↔ m3.xlarge, m2.2xlarge ↔ i2.xlarge and m2.4xlarge ↔ i2.2xlarge instance types. m2 instances have slightly, but not substantially more memory whereas m3 and i2 instances have either more or same number of vCPUs and way faster SSD disks.
-
I don’t believe low-end instances will be retired any time. AWS needs a broad range of instance types to cover different needs and the t1.micro and m1.small especially fill a need of as-cheap-as-possible instance types for situations with low performance requirements. It might become impossible to keep performance divide between m1.small hardware generations, in which case AWS might redefine m1.small’s performance characteristic upwards and move oldest hardware generations to serving t1 class instances (it is no coincidence that t1.micro’s maximum CPU performance is 2× m1.small’s).
If you want my guess on which instance types will be retired first, my guess is something from c1 or m2 classes. At least unless their prices get substantially cut to make them cost-competetive with m3 and i2 classes to keep demand (and cash flow) up.
How does this affect you?
First of all,
-
There is no way that the profileration of instance types won’t be followed by some sort of change. Whether it is a cull of instance types, redefinition of their specifications or something completely different, I don’t know. But I know that there is no sensible future where AWS can have gazillion instance types and still keep profitable and themselves and customers sane.
- Don’t specify instance types in code. The instance type used for
a particular purpose is configuration data (in launch
configuration, in configuration file etc.). If c1.medium is going
away then you’ll just need to grep config data and not the code
(which may construct
"c1.medium"as `“c1” + “.” +"medium"` which you won't find with simple grep at all). - Have a policy where production instances must be attributable.
If after all configuration references have been changed but you are
still seeing c1.medium instances it is super-useful that you can
determine what they are for and find the group / person
responsible. For this you can use tags like the built-in
Nameor introduce your own likeUnit,ProductorResponsible.
If you are concerned about instance availability,
- Do not rely on availability of an instance type. So you need more capacity but fail launching the super-price-optimal c3.2xlarge? Fall back and try launching two c3.xlarge instead, or c3.4xlarge or even c3.8xlarge. Or switch to g2.2xlarge or m2.2xlarge. The more heterogenous AWS’s instance lineup becomes the less likely I think there is going to be capacity in all instance types available all the time. (This applies only if you have your own instance management system, since AFAIK this is not possible with AWS auto scaling.)
And finally. My head hurts. Picking an “optimal” instance type is becoming more and more difficult. Yes, it is now possible to pick “more optimal” instance type than before, but finding that “more optimal” is taking more and more time than when there was a smaller number of instance types. (Will AWS abandon instance types at some point completely, allowing you to tune all the CPU/memory/disk parameters freely?)
This is starting to feel like the cereal aisle at the grocery store. Are you going to pick up the müsli with “berries and nuts” or “berries and plenty nuts” or “fresh nuts and berries” or “nut and berry extragavanza” or just “plain” or …
blog comments powered by Disqus